KI-Agenten sind 2026 nur dann produktiv, wenn Tool-Zugriffe, Datenflüsse, Guardrails und Evaluation sauber designt sind. Wenn Du „Agent“ sagst, aber eigentlich nur ein Chatfenster meinst, wirst Du in Produktion brennen.
Was wir 2026 wirklich mit „KI-Agent“ meinen
Ein System ist für uns erst dann ein Agent, wenn es:
- ein Ziel (Objective) versteht,
- Schritte plant (Plan → Execute),
- Tools nutzt (APIs, DBs, CMS, Ads Manager),
- Ergebnisse prüft (Guardrails/Evals),
- und einen Audit-Trail erzeugt (Logs, Entscheidungen, Inputs/Outputs).
Merksatz: Das Modell ist selten der Engpass. Die Integration + Kontrolle ist’s.
Referenzarchitektur (robust, nicht fancy)
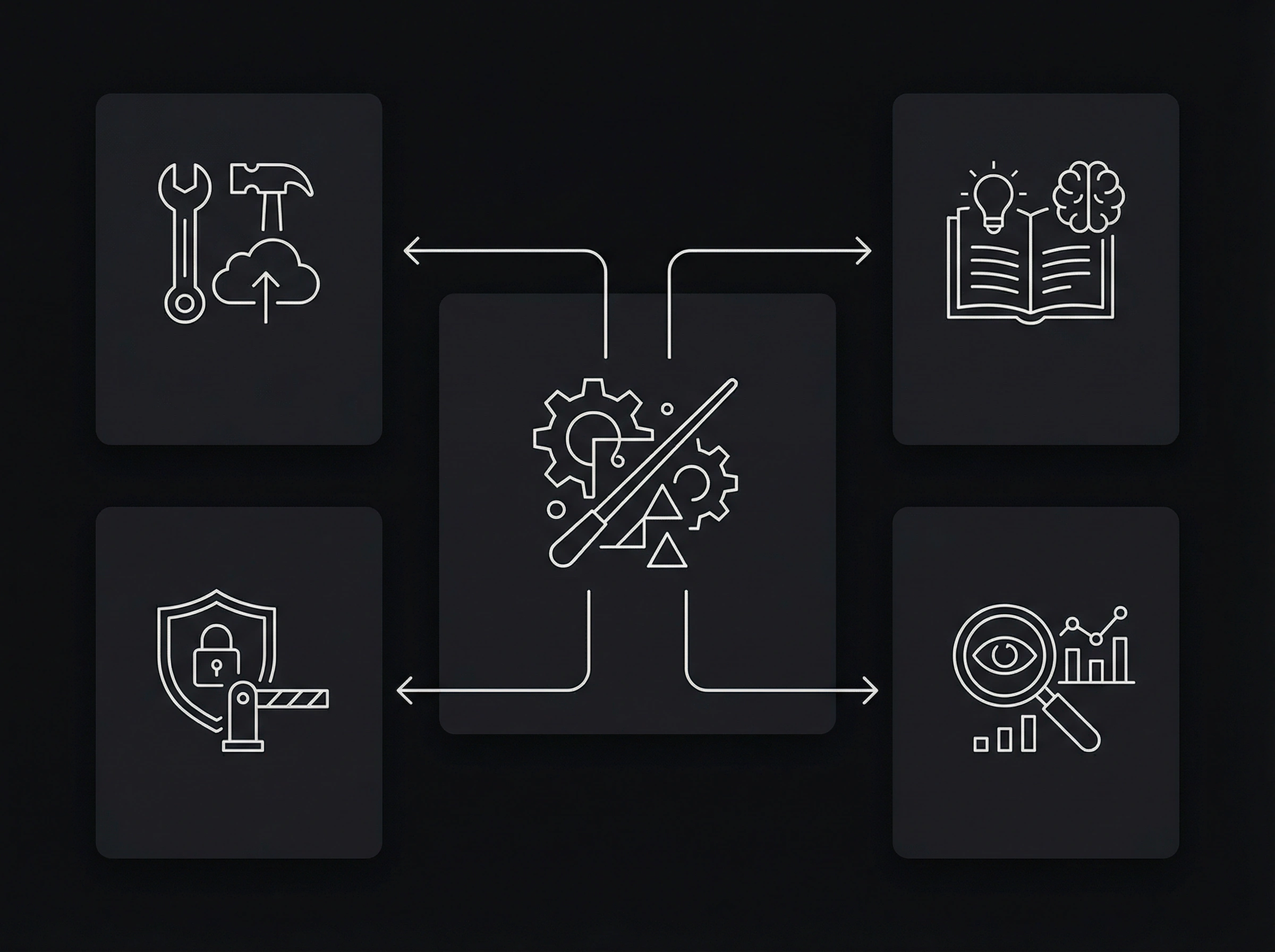
1) Orchestrierung (Agent Runtime)
- Routing & Zustandsmaschine (State)
- Timeouts / Retries / Abbruchkriterien
- Kostenlimits pro Run
Regel: Reasoning ≠ Execution. Secrets gehören nicht in Prompts.
2) Tools (mit minimalen Rechten)
Typische Marketing-/Content-Tools:
- CMS (Headless / Git / WordPress)
- Analytics (Plausible/GA4)
- Ads (Meta/Google)
- CRM (HubSpot/Pipedrive)
- Search Console
Least Privilege: Der Agent darf Drafts erstellen, nicht „Publish“.
3) Knowledge (RAG / Guidelines)
- Brand Voice (Beispiele, No-Gos)
- Services/Angebote + ICP
- Case Studies + Proof Points
- Compliance-Regeln
4) Guardrails (Policy Engine)
- PII-Filter
- Link-Checks
- Claims-Policy (siehe unten)
- Formatregeln (z.B. Listen statt Fließtext)
5) Evaluation & Observability (nicht optional)
Wenn Du nicht misst, rätst Du.
- Logging: Tool-Calls, Kosten, Laufzeit, Fehlertypen
- Qualitätsmetriken: Fact-Checks, Style-Checks, SEO-Checks
- Offline-Evals: Testset aus echten Briefings + Gold-Outputs
Failure-Modes, die wir ständig sehen (und die Fixes)
Agent macht „Tool-Spam“
Symptom:
- 12 API-Calls, aber keine Entscheidung.
Fix:
- Plan-Budget (max Schritte)
- harte Stop-Kriterien
- Definition of Done als Checkliste
Halluzinierte Features / Quellen
Fix:
- Konkrete Claims nur mit Primärquelle.
- Alles andere als Empfehlung/Erfahrung formulieren.
Unkontrolliertes Veröffentlichen
Fix:
- Human-in-the-loop (Freigabe) + getrennte Rollen/Keys.
ROI-Framework: So wird Agentenarbeit planbar
Wir messen ROI in vier Stufen:
- Effizienz: Minuten pro Asset, Kosten pro Asset
- Qualität: Fehlerquote, Review-Schleifen
- Performance: CTR/CVR/Rankings/Funnel-Metriken
- Lernen: Wie schnell fließen Learnings in Guidelines zurück?
- Agent darf nur Drafts erstellen (kein Auto-Publish)
- Tool-Rechte minimal (Least Privilege)
- Quellenpflicht für konkrete Claims
- Logging + Kostenlimits pro Run
- Testset für Evaluation (10–30 echte Briefings)
- Review-Flow: Wer prüft was?
Claims-Policy (für Triple A Digital)
- Produktfeatures/Benchmarks/Preise/rechtliche Aussagen: nur mit Primärquelle oder weglassen.
- Best Practices: als Empfehlung kennzeichnen.
- Zahlen: nur mit Quelle + Datum.
Nächster Schritt
Wenn Du willst, bauen wir Dir in 7–14 Tagen einen Agenten, der wöchentlich einen strukturierten Draft liefert (DE+EN), inklusive:
- Outline + Keywords
- Draft (MDX)
- Fact-check Liste
- Social Snippets
Sag uns kurz: Branche, Zielkunden (SMB/Enterprise) und welche Tools ihr nutzt – dann skizzieren wir die passende Architektur.