TL;DR
In 2026, agents only work in production if tool access, data flows, guardrails, and evaluation are designed properly. If your “agent” is just a chat box, it will melt the moment real systems are involved.
What we actually mean by “agent” in 2026
For us, an agent is a system that:
- understands an objective,
- can plan (plan → execute),
- uses tools (APIs, DBs, CMS, ads managers),
- checks results (guardrails/evals),
- and leaves an audit trail (logs, decisions, inputs/outputs).
Rule of thumb: The model is rarely the bottleneck. Integration + control is.
A boring reference architecture (that actually works)
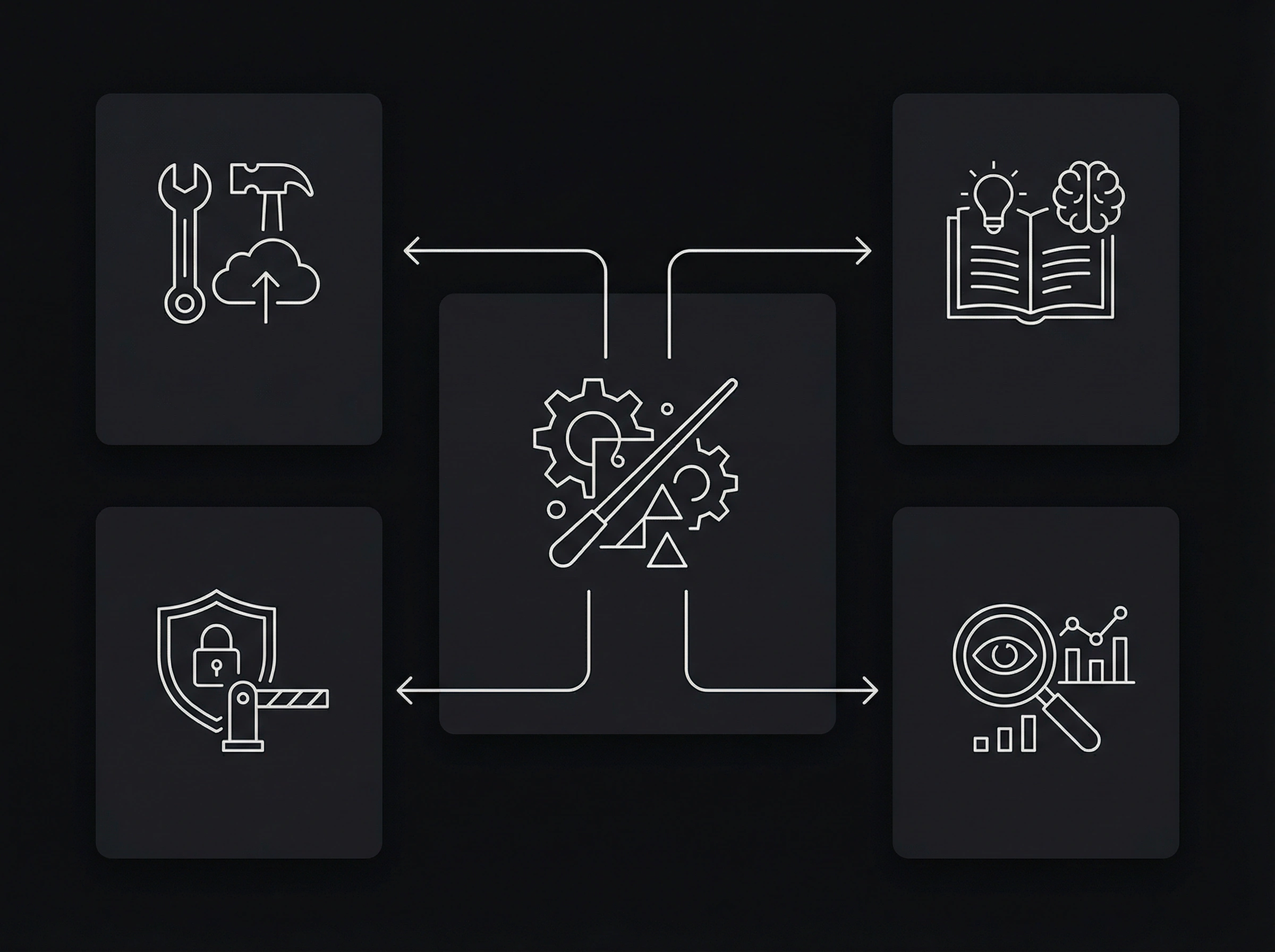
1) Orchestration (agent runtime)
- routing & state
- timeouts / retries / abort criteria
- cost limits per run
Rule: Reasoning ≠ execution. Secrets don’t belong in prompts.
2) Tools (minimum permissions)
Typical marketing/content tools:
- CMS (headless / git / WordPress)
- Analytics (Plausible/GA4)
- Ads (Meta/Google)
- CRM (HubSpot/Pipedrive)
- Search Console
Least privilege: drafts yes, auto-publish no.
3) Knowledge (RAG / guidelines)
- brand voice (examples, do/don’t)
- services/offers + ICP
- case studies + proof points
- compliance rules
4) Guardrails (policy engine)
- PII filters
- link checks
- claims policy
- formatting rules (lists > walls of text)
5) Evaluation & observability (not optional)
If you don’t measure, you’re guessing.
- logging: tool calls, cost, latency, error types
- quality: fact checks, style checks, SEO checks
- offline evals: real briefs + gold outputs
Failure modes we see all the time (and the fixes)
“Tool spam” instead of outcomes
Fix:
- step budget (max steps)
- hard stop criteria
- definition of done as a checklist
Hallucinated features / sources
Fix:
- concrete claims only with primary sources
- everything else framed as recommendations
Uncontrolled publishing
Fix:
- human-in-the-loop approvals + separate service accounts
ROI framework: make it measurable
We track four layers:
- Efficiency: minutes per asset, cost per asset
- Quality: error rate, review loops
- Performance: CTR/CVR/rankings/funnel metrics
- Learning: how fast learnings update guidelines
Production checklist (copy/paste)
- agent can only create drafts (no auto-publish)
- minimal tool scopes (least privilege)
- sources required for concrete claims
- logging + cost limits per run
- evaluation test set (10–30 real briefs)
- review flow: who approves what?
Claims policy (for Triple A Digital)
- product features/benchmarks/pricing/legal claims: primary source or remove
- best practices: label as recommendations
- numbers: source + date
Next step
If you want, we can build an agent in 7–14 days that ships a weekly structured draft (DE+EN), including:
- outline + keywords
- MDX draft
- fact-check list
- social snippets
Contact
Share your industry, target customers, and tooling stack — we’ll propose the right architecture.